資訊內容
python網絡爬蟲步驟是什么
python網絡爬蟲步驟:首先準備所需庫,編寫爬蟲調度程序;然后編寫url管理器,并編寫網頁下載器;接著編寫網頁解析器;**后編寫網頁輸出器即可。KeK少兒編程網-https://www.pxcodes.com
 KeK少兒編程網-https://www.pxcodes.com
KeK少兒編程網-https://www.pxcodes.com
本教程操作環境:windows7系統、python3.9版,DELL G3電腦。KeK少兒編程網-https://www.pxcodes.com
python網絡爬蟲步驟KeK少兒編程網-https://www.pxcodes.com
(1)準備所需庫KeK少兒編程網-https://www.pxcodes.com
我們需要準備一款名為BeautifulSoup(網頁解析)的開源庫,用于對下載的網頁進行解析,我們是用的是PyCharm編譯環境所以可以直接下載該開源庫。KeK少兒編程網-https://www.pxcodes.com
步驟如下:KeK少兒編程網-https://www.pxcodes.com
選擇File->SettingsKeK少兒編程網-https://www.pxcodes.com
 KeK少兒編程網-https://www.pxcodes.com
KeK少兒編程網-https://www.pxcodes.com
打開Project:PythonProject下的Project interpreterKeK少兒編程網-https://www.pxcodes.com
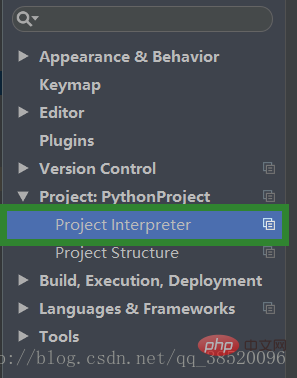 KeK少兒編程網-https://www.pxcodes.com
KeK少兒編程網-https://www.pxcodes.com
點擊加號添加新的庫KeK少兒編程網-https://www.pxcodes.com
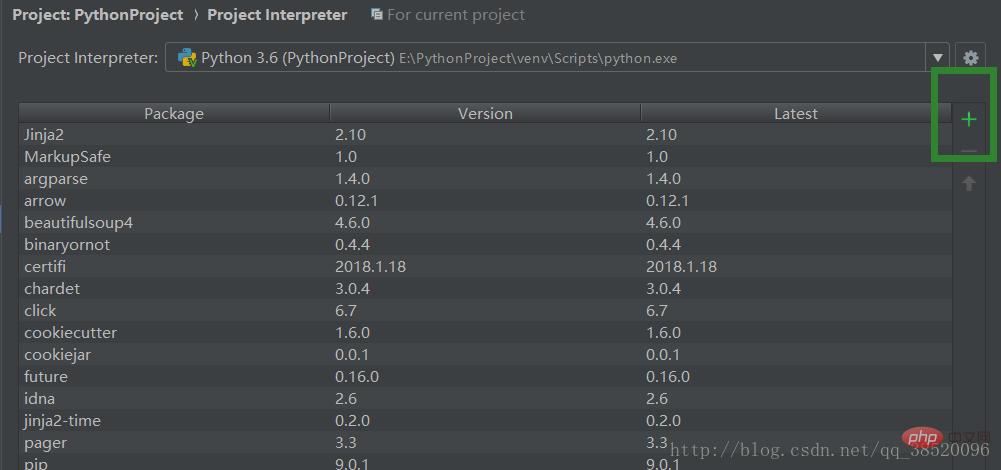 KeK少兒編程網-https://www.pxcodes.com
KeK少兒編程網-https://www.pxcodes.com
輸入bs4選擇bs4點擊Install Packge進行下載KeK少兒編程網-https://www.pxcodes.com
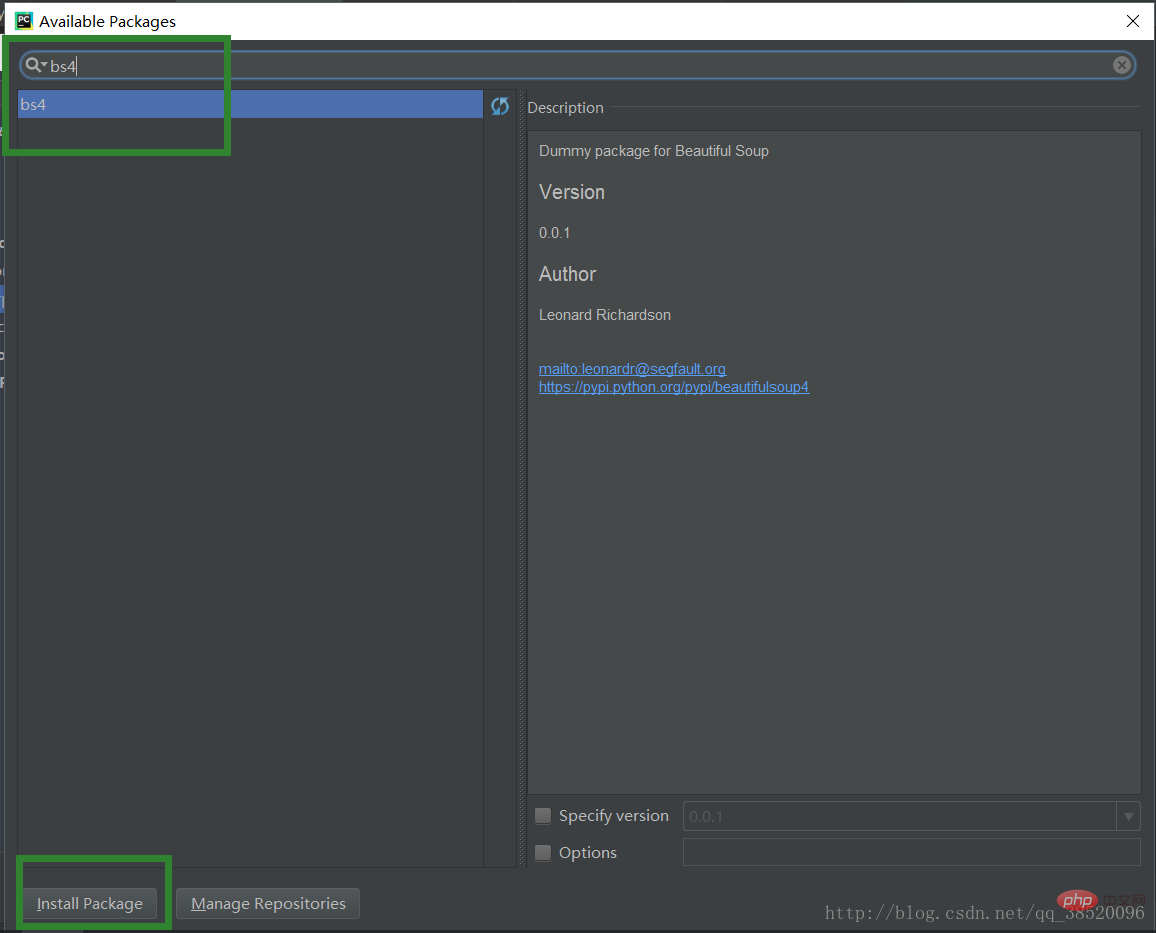 KeK少兒編程網-https://www.pxcodes.com
KeK少兒編程網-https://www.pxcodes.com
(2)編寫爬蟲調度程序KeK少兒編程網-https://www.pxcodes.com
這里的bike_spider是項目名稱引入的四個類分別對應下面的四段代碼url管理器,url下載器,url解析器,url輸出器。KeK少兒編程網-https://www.pxcodes.com
# 爬蟲調度程序 from bike_spider import url_manager, html_downloader, html_parser, html_outputer # 爬蟲初始化 class SpiderMain(object): def __init__(self): self.urls = url_manager.UrlManager() self.downloader = html_downloader.HtmlDownloader() self.parser = html_parser.HtmlParser() self.outputer = html_outputer.HtmlOutputer() def craw(self, my_root_url): count = 1 self.urls.add_new_url(my_root_url) while self.urls.has_new_url(): try: new_url = self.urls.get_new_url() print("craw %d : %s" % (count, new_url)) # 下載網頁 html_cont = self.downloader.download(new_url) # 解析網頁 new_urls, new_data = self.parser.parse(new_url, html_cont) self.urls.add_new_urls(new_urls) # 網頁輸出器收集數據 self.outputer.collect_data(new_data) if count == 10: break count += 1 except: print("craw failed") self.outputer.output_html() if __name__ == "__main__": root_url = "http://baike.baidu.com/item/Python/407313" obj_spider = SpiderMain() obj_spider.craw(root_url)(3)編寫url管理器KeK少兒編程網-https://www.pxcodes.com
我們把已經爬取過的url和未爬取的url分開存放以便我們不會重復爬取某些已經爬取過的網頁。KeK少兒編程網-https://www.pxcodes.com
# url管理器 class UrlManager(object): def __init__(self): self.new_urls = set() self.old_urls = set() def add_new_url(self, url): if url is None: return if url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) def add_new_urls(self, urls): if urls is None or len(urls) == 0: return for url in urls: self.new_urls.add(url) def get_new_url(self): # pop方法會幫我們獲取一個url并且移除它 new_url = self.new_urls.pop() self.old_urls.add(new_url) return new_url def has_new_url(self): return len(self.new_urls) != 0(4)編寫網頁下載器KeK少兒編程網-https://www.pxcodes.com
通過網絡請求來下載頁面KeK少兒編程網-https://www.pxcodes.com
# 網頁下載器 import urllib.request class HtmlDownloader(object): def download(self, url): if url is None: return None response = urllib.request.urlopen(url) # code不為200則請求失敗 if response.getcode() != 200: return None return response.read()(5)編寫網頁解析器KeK少兒編程網-https://www.pxcodes.com
對網頁進行解析時我們需要知道我們要查詢的內容都有哪些特征,我們可以打開一個網頁點擊右鍵審查元素來了解我們所查內容的共同之處。KeK少兒編程網-https://www.pxcodes.com
# 網頁解析器 import re from bs4 import BeautifulSoup from urllib.parse import urljoin class HtmlParser(object): def parse(self, page_url, html_cont): if page_url is None or html_cont is None: return soup = BeautifulSoup(html_cont, "html.parser", from_encoding="utf-8") new_urls = self._get_new_urls(page_url, soup) new_data = self._get_new_data(page_url, soup) return new_urls, new_data def _get_new_data(self, page_url, soup): res_data = {"url": page_url} # 獲取標題 title_node = soup.find("dd", class_="lemmaWgt-lemmaTitle-title").find("h1") res_data["title"] = title_node.get_text() summary_node = soup.find("p", class_="lemma-summary") res_data["summary"] = summary_node.get_text() return res_data def _get_new_urls(self, page_url, soup): new_urls = set() # 查找出所有符合下列條件的url links = soup.find_all("a", href=re.compile(r"/item/")) for link in links: new_url = link['href'] # 獲取到的url不完整,學要拼接 new_full_url = urljoin(page_url, new_url) new_urls.add(new_full_url) return new_urls(6)編寫網頁輸出器KeK少兒編程網-https://www.pxcodes.com
輸出的格式有很多種,我們選擇以html的形式輸出,這樣我們可以的到一個html頁面。KeK少兒編程網-https://www.pxcodes.com
# 網頁輸出器 class HtmlOutputer(object): def __init__(self): self.datas = [] def collect_data(self, data): if data is None: return self.datas.append(data) # 我們以html表格形式進行輸出 def output_html(self): fout = open("output.html", "w", encoding='utf-8') fout.write("<html>") fout.write("<meta charset='utf-8'>") fout.write("<body>") # 以表格輸出 fout.write("<table>") for data in self.datas: # 一行 fout.write("<tr>") # 每個單元行的內容 fout.write("<td>%s</td>" % data["url"]) fout.write("<td>%s</td>" % data["title"]) fout.write("<td>%s</td>" % data["summary"]) fout.write("</tr>") fout.write("</table>") fout.write("</body>") fout.write("</html>") # 輸出完畢后一定要關閉輸出器 fout.close()相關免費學習推薦:python視頻教程KeK少兒編程網-https://www.pxcodes.com
以上就是python網絡爬蟲步驟是什么的詳細內容,更多請關注少兒編程網其它相關文章!KeK少兒編程網-https://www.pxcodes.com

- 上一篇

Pycharm如何給項目配置python解釋器
簡介Pycharm給項目配置python解釋器的方法:首先打開Pycharm,選擇settings選項;然后選擇project選項,并選擇ProjectInterpreter選項;接著選擇Python環境;最后點擊ok按鈕。本教程操作環境:windows7系統、python3.9版,DELLG3電腦。P
- 下一篇

學習python將中文數字轉化成阿拉伯數字
簡介python將中文數字轉化成阿拉伯數字正則表達式提取文本中的數字中文轉化成阿拉伯數字完整代碼(免費學習推薦:python視頻教程)正則表達式提取文本中的數字這里演示一下文本中提取中文年份importrem0=在一九四九年新中國成立比一九九零年低百分之五點二人一九九六年擊敗俄軍,取得實質獨
相關資訊
