資訊內容
重磅!MobileNetV3 來了!
點擊上方“計算機視覺life”,選擇“置頂”

本文轉載自我愛計算機視覺,禁二次轉載
在現代深度學習算法研究中,通用的骨干網+特定任務網絡head成為一種標準的設計模式。比如VGG + 檢測Head,或者inception + 分割Head。
在移動端部署深度卷積網絡,無論什么視覺任務,選擇高精度的計算量少和參數少的骨干網是必經之路。這其中谷歌家去年發布的 MobileNetV2是首選。
在MobileNetV2論文發布時隔一年4個月后,MobileNetV3 來了!
這必將引起移動端網絡升級的狂潮,讓我們一起來看看這次又有什么黑科技!
昨天谷歌在arXiv上公布的論文《Searching for MobileNetV3》,詳細介紹了MobileNetV3的設計思想和網絡結構。

先來說下結論:MobileNetV3 沒有引入新的 Block,題目中Searching已經道盡該網絡的設計哲學:神經架構搜索!
研究人員公布了 MobileNetV3 有兩個版本,MobileNetV3-Small 與?MobileNetV3-Large 分別對應對計算和存儲要求低和高的版本。
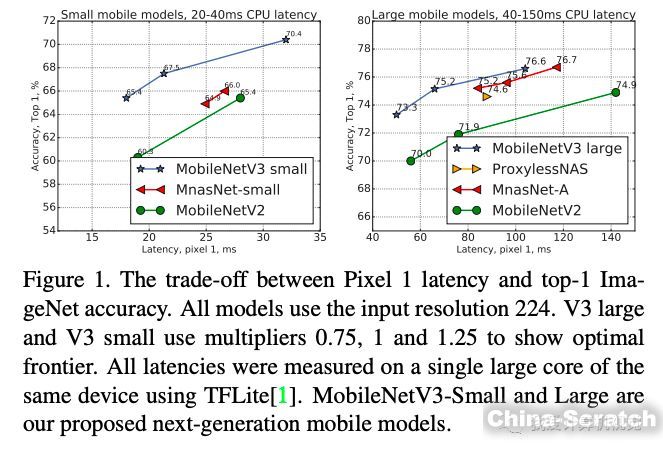
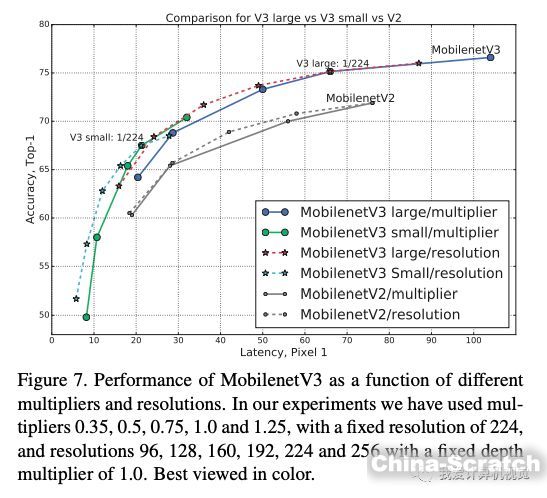
下圖分別是MobileNetV3兩個版本與其他輕量級網絡在Pixel 1 手機上的計算延遲與ImageNet分類精度的比較。可見MobileNetV3 取得了顯著的比較優勢。
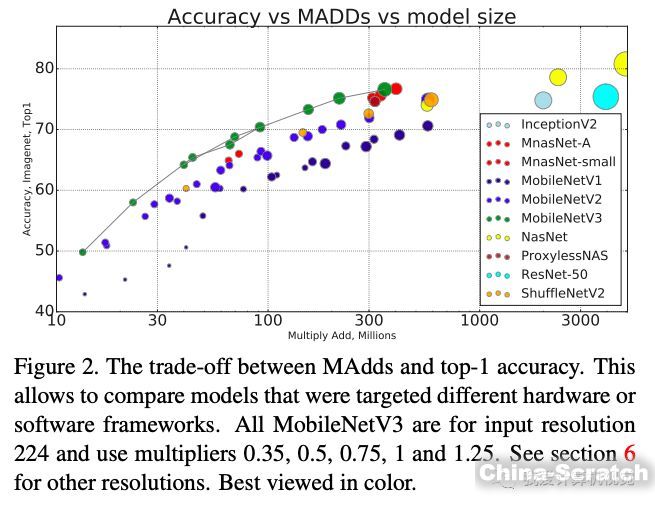
下圖是ImageNet分類精度、MADD計算量、模型大小的比較,MobileNetV3依然是最優秀的。
高效的網絡構建模塊
前面已經說過,MobileNetV3 是神經架構搜索得到的模型,其內部使用的模塊繼承自:
1. MobileNetV1 模型引入的深度可分離卷積(depthwise separable convolutions);
2. MobileNetV2 模型引入的具有線性瓶頸的倒殘差結構(the inverted residual with linear bottleneck);
3. MnasNet 模型引入的基于squeeze and excitation結構的輕量級注意力模型。
這些被證明行之有效的用于移動端網絡設計的模塊是搭建MobileNetV3的積木。
互補搜索
在網絡結構搜索中,作者結合兩種技術:資源受限的NAS(platform-aware NAS)與NetAdapt,前者用于在計算和參數量受限的前提下搜索網絡的各個模塊,所以稱之為模塊級的搜索(Block-wise Search)?,后者用于對各個模塊確定之后網絡層的微調。
這兩項技術分別來自論文:
M. Tan, B. Chen, R. Pang, V. Vasudevan, and Q. V. Le. Mnasnet: Platform-aware neural architecture search for mobile. CoRR, abs/1807.11626, 2018.?
T. Yang, A. G. Howard, B. Chen, X. Zhang, A. Go, M. Sandler, V. Sze, and H. Adam. Netadapt: Platform-aware neural network adaptation for mobile applications. In ECCV, 2018
前者相當于整體結構搜索,后者相當于局部搜索,兩者互為補充。
到這里,我們還沒看到算法研究人員的工作在哪里(啟動訓練按鈕?)
繼續往下看。
網絡改進
作者們發現MobileNetV2 網絡端部最后階段的計算量很大,重新設計了這一部分,如下圖:
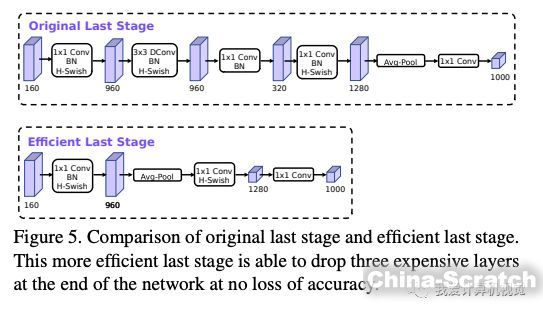
這樣做并不會造成精度損失。
另外,作者發現一種新出的激活函數swish x 能有效改進網絡精度:
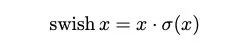
但就是計算量太大了。
于是作者對這個函數進行了數值近似:
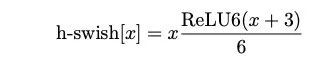
事實證明,這個近似很有效:
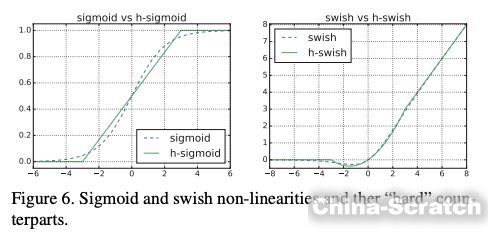
從圖形上看出,這兩個函數的確很接近。
MobileNetV3 網絡結構!
這就是今天的主角了!
使用上述搜索機制和網絡改進,最終谷歌得到的模型是這樣(分別是MobileNetV3-Large和MobileNetV3-Small):
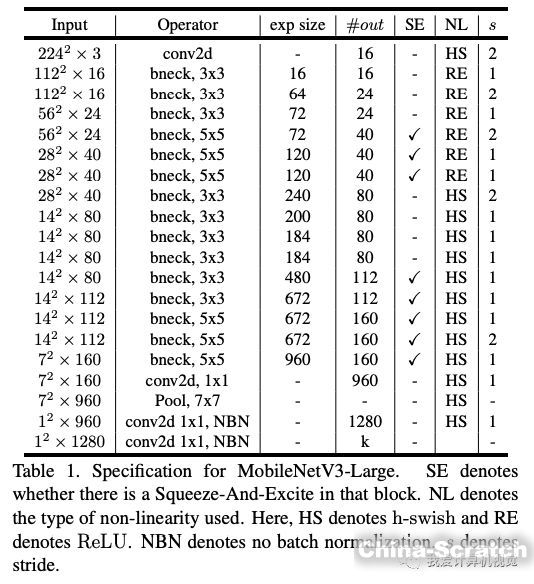
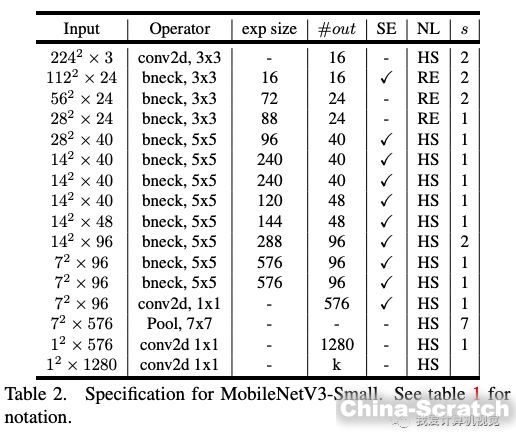
內部各個模塊的類型和參數均已列出。
谷歌沒有公布用了多少時間搜索訓練。
目前谷歌還沒有公布MobileNetV3的預訓練模型,不過讀者可以按照上述結構構建網絡在ImageNet上訓練得到權重。
實驗結果
作者使用上述網絡在分類、目標檢測、語義分割三個任務中驗證了MobileNetV3的優勢:在計算量小、參數少的前提下,相比其他輕量級網絡,依然在在三個任務重取得了最好的成績。
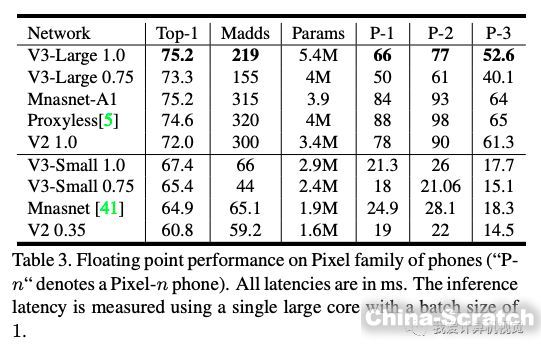
下圖是ImageNet分類Top-1精度、計算量、參數量及在Pixel系列手機實驗的結果:
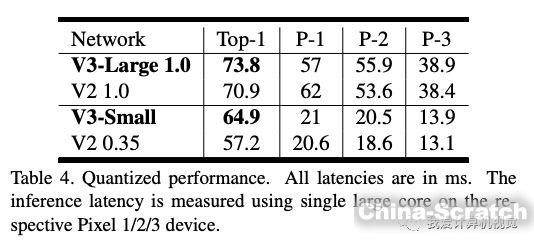
下圖是與前一代MobieNetV2的比較結果:
這是使用其構筑的SSDLite目標檢測算法在MS COCO數據集上的比較結果:
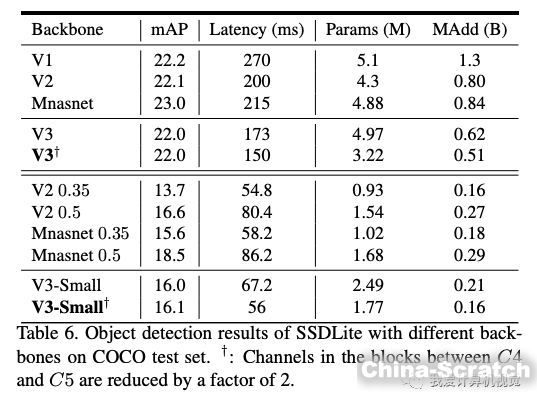
V3-Large取得了最高的精度,V3-Small 取得了V2近似的精度,速度卻快很多。
另外作者基于MobieNetV3設計了新的輕量級語義分割模型Lite R-ASPP:
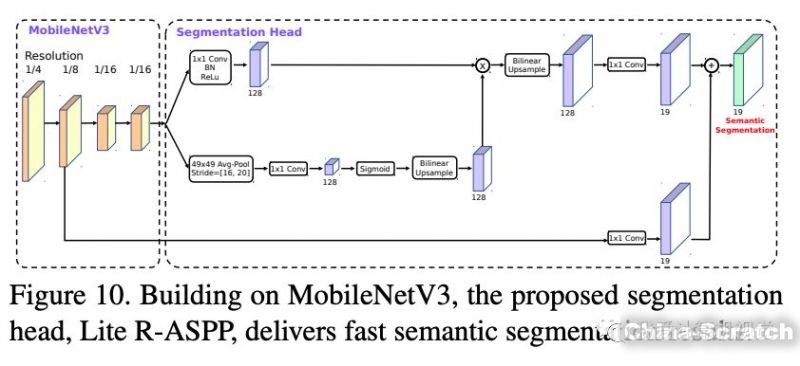
下圖是使用上述分割算法在CItyScapes驗證集上的結果比較:
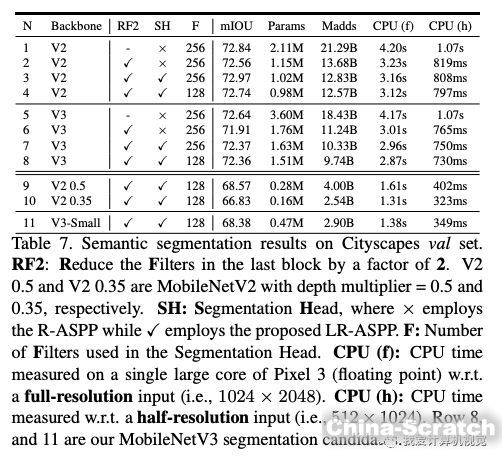
精度提升不明顯,速度有顯著提升。
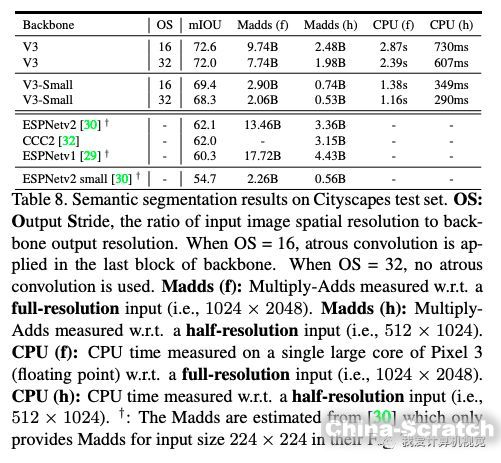
下圖是與其他輕量級語義分割算法的比較,MobileNetV3取得了不小的優勢。
總結一下:
MobileNetV3-Large在ImageNet分類上的準確度與MobileNetV2相比提高了3.2%,同時延遲降低了15%。
MobileNetV3-large 用于目標檢測,在COCO數據集上檢測精度與MobileNetV2大致相同,但速度提高了25%。
在Cityscapes語義分割任務中,新設計的模型MobileNetV3-Large LR-ASPP 與 MobileNetV2 R-ASPP分割精度近似,但快30%。
期待谷歌早日將其預訓練模型開源~
神經架構搜索火了,但感覺是不是算法設計也越來越乏味了。。。
歡迎發表你的看法。
推薦閱讀
CVPR2019 | Decoders 對于語義分割的重要性CVPR2019?|?R-MVSNet:?一個高精度高效率的三維重建網絡CVPR2019 | SiamMask:視頻跟蹤最高精度
CVPR 2019 | 用異構卷積訓練深度CNN:提升效率而不損準確度
CVPR 2019 | 人大 ML 研究組提出新的視頻測謊算法
CVPR2019 | 醫學影像:MIT 利用學習圖像變換進行數據增強CVPR 2019 | GeoNet:基于測地距離的點云分析深度網絡
CVPR2019 | 中科大&微軟開源:姿態估計新模型HRNet
CVPR 2019 | 京東提出 ScratchDet:隨機初始化訓練SSD目標檢測器
CVPR 2019 | 微軟亞研院提出用于語義分割的結構化知識蒸餾
CVPR2019 | 6D目標姿態估計,李飛飛等提出DenseFusion
CVPR 2019 | PointConv:在點云上高效實現卷積操作
CVPR 2019 | 圖像壓縮重建也能抵御對抗樣本
CVPR 2019 | 神奇的超分辨率算法DPSR:應對圖像模糊降質綜述 | CVPR2019目標檢測方法進展
聲明:本文章由網友投稿作為教育分享用途,如有侵權原作者可通過郵件及時和我們聯系刪除


相關資訊
