資訊內容
python3爬蟲入門:常用網絡爬蟲模塊和技術
urllib模塊qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
urllib庫是python中自帶的模塊,也是一個**基本的網絡請求庫,該模塊提供了一個urlopen()方法,通過該方法指定URL發送網絡請求來獲取數據。qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
urllib 是一個收集了多個涉及 URL 的模塊的包
qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
urllib.request 打開和讀取 URL
qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
三行代碼即可爬取百度首頁源代碼:qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
import urllib.request # 打開指定需要爬取的網頁 response=urllib.request.urlopen('http://www.baidu.com') # 或者是 # from urllib import request # response = request.urlopen('http://www.baidu.com') # 打印網頁源代碼 print(response.read().decode())加入decode()是為了避免出現下圖中十六進制內容qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
 qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
加入decode()進行解碼后qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
 qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
下面三種本篇將不做詳述qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
urllib.error 包含 urllib.request 拋出的異常qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
urllib.parse 用于解析 URLqOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
urllib.robotparser 用于解析 robots.txt 文件qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
requests模塊qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
requests模塊是python中實現HTTP請求的一種方式,是第三方模塊,該模塊在實現HTTP請求時要比urllib模塊簡化很多,操作更加人性化。qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
以GET請求為例:qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
import requests response = requests.get('http://www.baidu.com/') print('狀態碼:', response.status_code) print('請求地址:', response.url) print('頭部信息:', response.headers) print('cookie信息:', response.cookies) # print('文本源碼:', response.text) # print('字節流源碼:', response.content)輸出結果如下:qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
狀態碼: 200 請求地址: http://www.baidu.com/ 頭部信息: {'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Sun, 10 May 2020 02:43:33 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:28:23 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'} cookie信息: <RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>這里講解一下response.text和 response.content的區別:qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
response.content是直接從網絡上面抓取的數據,沒有經過任何解碼,所以是一個 bytes類型
qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
response.text是將response.content進行解碼的字符串,解碼需要指定一個編碼方式, requests會根據自己的猜測來判斷編碼的方式,所以有時候可能會猜測錯誤,就會導致解碼產生亂碼,這時候就應該使用 response.content.decode(‘utf-8’)qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
進行手動解碼qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
以POST請求為例qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
import requests data={'word':'hello'} response = requests.post('http://www.baidu.com',data=data) print(response.content)請求headers處理qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
當爬取頁面由于該網頁為防止惡意采集信息而使用反爬蟲設置,從而拒絕用戶訪問,我們可以通過模擬瀏覽器的頭部信息來進行訪問,這樣就能解決反爬蟲設置的問題。qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
通過瀏覽器進入指定網頁,右擊鼠標,選中“檢查”,選擇“Network”,刷新頁面后選擇第一條信息,右側消息頭面板將顯示下圖中請求頭部信息qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
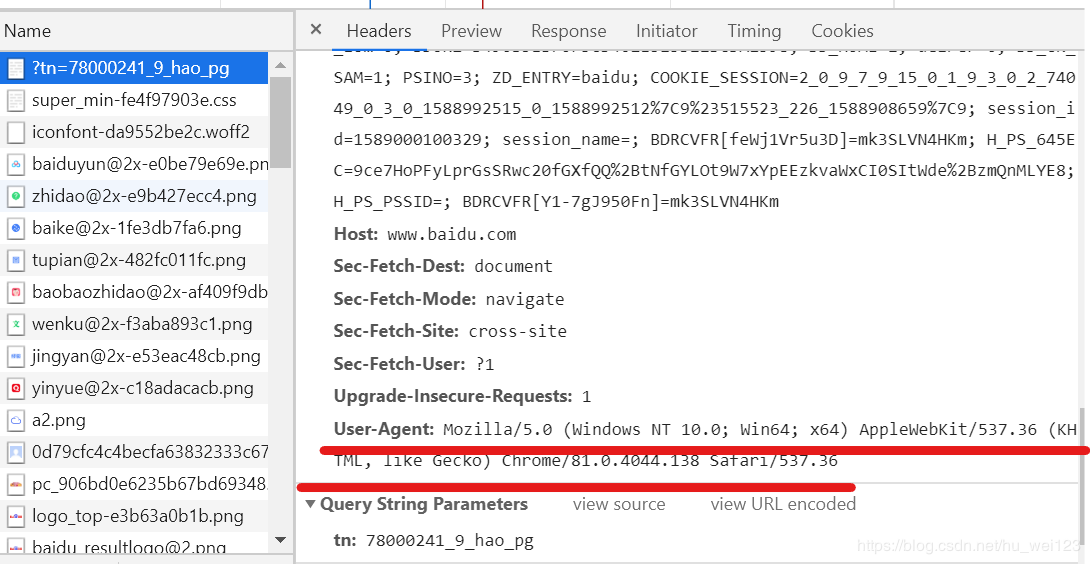 qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
例如:qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
import requests url = 'https://www.bilibili.com/' headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'} response = requests.get(url, headers=headers) print(response.content.decode())網絡超時qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
在訪問一個頁面,如果該頁面長時間未響應,系統就會判斷該網頁超時,所以無法打開網頁。qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
例如:qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
import requests url = 'http://www.baidu.com' # 循環發送請求50次 for a in range(0, 50): try: # timeout數值可根據用戶當前網速,自行設置 response = requests.get(url, timeout=0.03) # 設置超時為0.03 print(response.status_code) except Exception as e: print('異常'+str(e)) # 打印異常信息部分輸出結果如下:qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
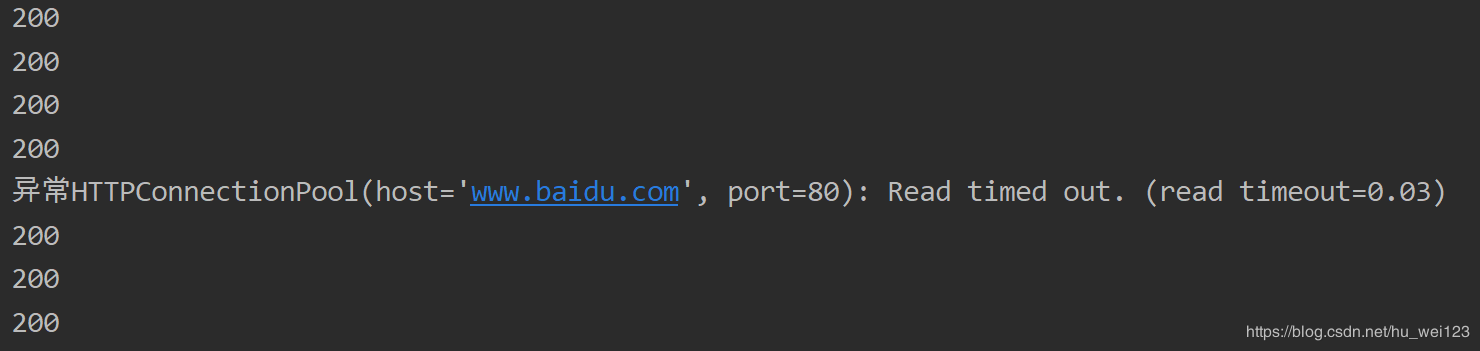 qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
代理服務
qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
設置代理IP可以解決不久前可以爬取的網頁現在無法爬取了,然后報錯——由于連接方在一段時間后沒有正確答復或連接的主機沒有反應,連接嘗試失敗的問題。qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
以下網站可以提供免費代理IP https://www.xicidaili.com/例如:qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
import requests # 設置代理IP proxy = {'http': '117.45.139.139:9006', 'https': '121.36.210.88:8080' } # 發送請求 url = 'https://www.baidu.com' response = requests.get(url, proxies=proxy) # 也就是說如果想取文本數據可以通過response.text # 如果想取圖片,文件,則可以通過 response.content # 以字節流的形式打印網頁源代碼,bytes類型 print(response.content.decode()) # 以文本的形式打印網頁源代碼,為str類型 print(response.text) # 默認”iso-8859-1”編碼,服務器不指定的話是根據網頁的響應來猜測編碼。Beautiful Soup模塊qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
Beautiful Soup模塊是一個用于HTML和XML文件中提取數據的python庫。Beautiful Soup模塊自動將輸入的文檔轉換為Unicode編碼,輸出文檔轉換為UTF-8編碼,你不需要考慮編碼方式,除非文檔沒有指定一個編碼方式,這時,Beautiful Soup就不能自動識別編碼方式了,然后,僅僅需要說明一下原始編碼方式就可以了。qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
例如:qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
from bs4 import BeautifulSoup html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ # 創建對象 soup = BeautifulSoup(html_doc, features='lxml') # 或者創建對象打開需要解析的html文件 # soup = BeautifulSoup(open('index.html'), features='lxml') print('源代碼為:', soup)# 打印解析的HTML代碼運行結果如下:qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
<html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> </body></html>用Beautiful Soup爬取百度首頁標題qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
from bs4 import BeautifulSoup import requests response = requests.get('http://news.baidu.com') soup = BeautifulSoup(response.text, features='lxml') print(soup.find('title').text)運行結果如下:qOD少兒編程網-Scratch_Python_教程_免費兒童編程學習平臺
百度新聞——海量中文資訊平臺
- 上一篇

Python之自動獲取目標網站最新通知
簡介Python之自動獲取目標網站最新通知:1、建立通知數據庫這一步的目的是爬取目標網站已經發布的通知的數據,并進行存儲,從而建立與該目標網站內容相對應的本地數據庫。考慮到數據庫中的數據將是辨別和獲取一則新通知的唯一方法,因此所建立的數據庫將存儲每一條通知的標題、發布日期和訪問鏈接。第一步使用到的模塊有
- 下一篇

Python中的進度條progressbar,讓進度直觀顯示!
簡介今天突然被問了一個問題:程序在執行中很久不結束是怎么回事?看不到程序執行的進度,在我們進行大工程的時候的確是一件很頭疼的事,本文讓我們來了解一個很常用的進度條展示小工具——Progressbar。注:最新版的使用者不要照著GitHub上的官方文檔去操作,文檔信息沒有維護,會出現很多問題。下載模塊pi
相關資訊
