課程內(nèi)容
Python入門課程N(yùn)O67課 文件的讀寫高級操作
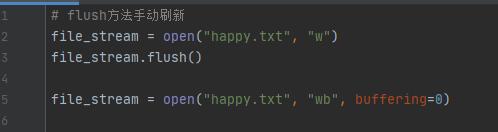
文件的讀寫緩沖區(qū):
文件的讀寫緩沖區(qū)對應(yīng)的是內(nèi)存中的一塊緩沖區(qū):在對文件執(zhí)行寫操作時(shí),會(huì)先將數(shù)據(jù)寫到這個(gè)緩沖區(qū),緩沖區(qū)寫滿以后再刷新到磁盤。在對文件執(zhí)行讀操作時(shí),會(huì)先將文件的一部分?jǐn)?shù)據(jù)預(yù)讀到這塊內(nèi)存緩沖區(qū),然后再從這塊緩沖區(qū)里進(jìn)行讀取。在內(nèi)存中進(jìn)行讀寫遠(yuǎn)快于直接在磁盤中進(jìn)行讀寫,所以在寫入的時(shí)候,先寫到內(nèi)存緩沖區(qū),當(dāng)數(shù)據(jù)量大于內(nèi)存緩沖區(qū)的容量時(shí),再一次性刷新到磁盤。讀取也是一樣的道理,先將磁盤文件中的一批數(shù)據(jù)預(yù)讀到內(nèi)存里來,后續(xù)讀取的時(shí)候直接在內(nèi)存緩沖區(qū)里進(jìn)行讀操作,大大提高了讀取的性能。
可以通過執(zhí)行文件流對象flush方法手動(dòng)地刷新內(nèi)存緩沖區(qū)。
另外open方法中有一個(gè)buffering參數(shù),當(dāng)給buffering參數(shù)傳遞0時(shí),會(huì)關(guān)閉這個(gè)內(nèi)存緩沖區(qū),該操作只適用于二進(jìn)制模式。傳遞1時(shí)設(shè)置行緩沖模式,只能用于文本模式。所謂的行緩沖是指一行緩沖的大小,這里的一行以行尾的換行符來進(jìn)行標(biāo)識。傳遞的值大于1時(shí)表示設(shè)置固定的緩沖區(qū)大小。
文件的指針與定位:
file_stream.seek(offset, [from]):offset表示是偏移量,from表示從什么位置處開始進(jìn)行定位,from的值為0時(shí)表示從文件頭開始定位,為1時(shí)表示從當(dāng)前位置開始定位,為2時(shí)表示從文件尾開始定位。from的值默認(rèn)為0。如需從當(dāng)前位置進(jìn)行定位,必須以二進(jìn)制模式來打開文件。

可以把文件指針形象地理解為箭頭,一開始這個(gè)箭頭指向文件的首行,應(yīng)用程序讀取文件時(shí),從箭頭指向的位置處開始讀取。每讀完一行,箭頭就下移一行。
指定文件編碼:
在執(zhí)行open函數(shù)獲取文件流對象時(shí),可以通過encoding參數(shù)來指定文件讀寫時(shí)的編碼。只有當(dāng)文件自身編碼和代碼書寫編碼保持一致時(shí),才能正確的讀取文件內(nèi)容,否則將拋出異常。例如我們用編輯器打開hello.txt輸入極客小將四個(gè)字,之后保存為uft-8編碼格式。

如果我們改成以ascii編碼方式讀取,那么就會(huì)拋出錯(cuò)誤異常。

值得一提的是可以utf-8編碼讀取ascii編碼的文件,因?yàn)閡tf-8字符集涵蓋了ascii字符集,所以使用utf-8編碼來讀取文件時(shí),能正確的編解碼,而不會(huì)拋出異常信息。
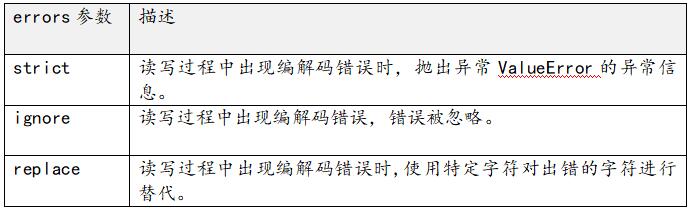
對文件讀寫進(jìn)行錯(cuò)誤處理:open方法中的errors參數(shù),用來控制出現(xiàn)編碼和解碼的錯(cuò)誤時(shí)該如何處理。errors參數(shù)只能用于文本模式。
舉例說明:


- 上一篇
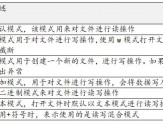
Python入門課程N(yùn)O66課 文件的讀寫操作
在Python中可以通過內(nèi)置的open函數(shù)來對文件進(jìn)行讀寫操作。open(file, mode, buffering, encoding,errors)。file 對應(yīng)的是文件的路徑名,mode 對應(yīng)的是文件的打開模式,buffering對應(yīng)的是文件緩沖,encoding對應(yīng)的是文件數(shù)據(jù)流的編碼, errors表示的是對文件的讀寫過程中出現(xiàn)了
- 下一篇
Python入門課程N(yùn)O68課 StringIO與BytesIO
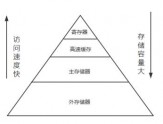
我們通過open方法來打開硬盤上的文件,并獲得一個(gè)文件流對象,然后通過文件流對象對文件進(jìn)行讀寫操作。計(jì)算機(jī)中的存儲設(shè)備按其訪問速度和容量大小,被組織成了下圖所示的金字塔形狀的層次結(jié)構(gòu):我們讀寫的硬盤文件,存儲在外存儲器中,從圖可看出在硬盤中進(jìn)行數(shù)據(jù)讀寫,遠(yuǎn)慢于
